%%HTML
'''0_0'''
import importlib
import LIMU
import torch
from torch import nn
from torch.nn import functional as F
绘制图表时,使用svg格式,清晰度高。
%config InlineBackend.figure_format = 'svg'
'''0_1'''
Jupyter,如果LIMU模块有变化,需要重新加载。
importlib.reload(LIMU)
from LIMU import Chapter00, Chapter01
'''0_2'''
MacBook没有CUDA。
torch.cuda.device_count()
对于Windows+Nvidia,可以用cuda。
y = torch.tensor([1,2,3], device='cuda')
对于MacBook,用mps。
y = torch.tensor([1,2,3], device='mps')
print(y)
卷积层
假设我们有一个输入图像$G$和一个卷积核$K$。
互相关 "Cross-correlation":直接将卷积核$K$在图像$G$上滑动,对应位置相乘再求和。
$$ (G ★ K)(i, j) = \sum_m \sum_n G(i+m, j+n) K(m, n) $$
卷积 "Convolution":先将卷积核$K$上下翻转再左右翻转,(其实相当于逆时针旋转180°),然后执行互相关操作。
$$ (G ☆ K)(i, j) = \sum_m \sum_n G(i-m, j-n) K(m, n) $$
其中,$i, j$是输出特征图的坐标,$m, n$是卷积核内的坐标,直观理解,输出$(i, j)$时,
- 互相关,卷积核右下角$K(m, n)$对应图像的右下角$G(i+m, j+n)$
- 卷积,卷积核右下角$K(m, n)$对应图像的左上角$G(i-m, j-n)$
在PyTorch、TensorFlow等深度学习框架中,nn.Conv2d等所谓的“卷积层”,实际上执行的是互相关运算,没有翻转核。
结果是等价的,因为权重是学出来的,所以翻不翻转无所谓,大家就习惯性地叫它卷积了。。。
“卷积核”"Kernel"又被称为“滤波器”"Filter"。
'''1_1'''
def cross_correl_2d(X_2D, K_2D):
"""二维互相关运算。"""
m, n = K_2D.shape
Y_2D = torch.zeros((X_2D.shape[0] - m + 1, X_2D.shape[1] - n + 1))
for i in range(Y_2D.shape[0]):
for j in range(Y_2D.shape[1]):
torch.mul():哈达玛积"HadamardProduct",逐元素乘法,不求和。
Y_2D[i, j] = torch.mul(X_2D[i:i+m, j:j+n], K_2D).sum()
return Y_2D
X_2D = torch.arange(9.).view(3, 3)
K_2D = torch.arange(4.).view(2, 2)
cross_correl_2d(X_2D, K_2D)
若输入图像的高宽分别为$(I_h, I_w)$,卷积核的高宽分别为$(f_h, f_w)$,步长为$(s_h, s_w)$,填充为$(p_h, p_w)$,左右各填充$p_w$个像素,上下各填充$p_h$个像素,
则卷积核的输出大小为$(I_h - f_h + 2p_h) / s_h + 1, (I_w - f_w + 2p_w) / s_w + 1$。
一般取$p_h = (f_h - 1) / 2, p_w = (f_w - 1) / 2$,$f_h, f_w$都取奇数,$I_h, I_w$可被$s_h, s_w$整除,输出大小为$(O_h, O_w) = (I_h / s_h, I_w / s_w)$。
多通道"Channel"情况,灰度图像为1通道,彩色图像为3通道。
输入$I: (C_i, I_h, I_w)$,核$K: (C_o, C_i, K_h, K_w)$,输出$O: (C_o, O_h, O_w)$,
通道数与图像无关,这里是$C_o, C_i$而不是$O_c, I_c$,$C_o$为输出通道数,$C_i$为输入通道数。
'''1_2'''
cross_correl_2d_ci = lambda X_3D, K_3D: torch.stack(
[cross_correl_2d(X_2D, K_2D) for X_2D, K_2D in zip(X_3D, K_3D)]).sum(dim=0)
cross_correl_2d_ci_co = lambda X_3D, K_4D: torch.stack(
[cross_correl_2d_ci(X_3D, K_3D) for K_3D in K_4D], 0)
X_3D = torch.arange(9.).view(1, 3, 3) + torch.arange(2.).view(2, 1, 1)
K_3D = torch.arange(4.).view(1, 2, 2) + torch.arange(2.).view(2, 1, 1)
X_3D = tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K_3D = tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
X_3D.shape, K_3D.shape = torch.Size([2, 3, 3]), torch.Size([2, 2, 2])
K_4D = torch.stack([K_3D, K_3D + 1, K_3D + 2], 0)
K_4D = tensor([[[[0., 1.], [2., 3.]], [[1., 2.], [3., 4.]]],
[[[1., 2.], [3., 4.]], [[2., 3.], [4., 5.]]],
[[[2., 3.], [4., 5.]], [[3., 4.], [5., 6.]]]])
K_4D.shape = torch.Size([3, 2, 2, 2])
cross_correl_2d_ci_co(X_3D, K_4D).shape
池化层
也称为“下采样”"Subsampling"或“汇聚层”"Pooling",是卷积神经网络(CNN)中常用的一种组件,通常紧跟在卷积层之后。
它的核心作用是压缩数据:在保留主要特征的同时,减小特征图(Feature Map)的空间尺寸(高和宽)。
为什么要用池化层?
- 降低计算量:通过减小图片的尺寸,减少下一层网络的参数数量和计算负载。
- 防止过拟合:减少了特征数量,降低了模型对具体位置的过度依赖。
- 平移不变性(Translation Invariance):这是最重要的特性之一。如果输入图像中的物体稍微移动了一点,池化后的输出可能保持不变(因为我们取的是局部区域的最大值或平均值)。这让模型对物体的位置变化更健壮。
最常用的两种是 最大池化 和 平均池化 。
最大池化 Max Pooling
操作:在滑动窗口内取最大值,它就像在问“这个区域内有没有出现过某种特征(比如垂直边缘)?”如果有(值很大),就保留下来。它倾向于保留最显著的纹理特征。
平均池化 Average Pooling
操作:在滑动窗口内取平均值,它保留了背景的平均信息,通常用于平滑图像。
'''1_3'''
def pool_max_2d(X_2D, pool_size, mode=True):
"""二维最大池化运算。"""
m, n = pool_size
Y_2D = torch.zeros((X_2D.shape[0] - m + 1, X_2D.shape[1] - n + 1))
for i in range(Y_2D.shape[0]):
for j in range(Y_2D.shape[1]):
if mode:
Y_2D[i, j] = X_2D[i:i+m, j:j+n].max()
else:
Y_2D[i, j] = X_2D[i:i+m, j:j+n].mean()
return Y_2D
带小数点,指定是浮点型。
X_2D = torch.arange(9.).view(3, 3)
print(pool_max_2d(X_2D, (2, 2)))
mean()方法只接受浮点型。
print(pool_max_2d(X_2D, (2, 2), False))
LeNet
由深度学习三巨头之一的 Yann LeCun 在1998年提出。
定义了现代卷积神经网络的基本组件:卷积层(Convolution)、池化层(Pooling)和全连接层(Fully Connected)。它最初被设计用于识别手写数字(MNIST 数据集),并在当时取得了巨大的成功,被广泛应用于美国银行的支票手写数字识别中。
- LeNet-5的输入通常是MNIST的灰度图像$1×28×28$,上下左右各填充$2$。
- C1卷积层 (Conv1): 使用6个$5×5$的卷积核。输出特征图大小:$6×28×28$,因为$28+2×2-5+1=28$。
- S2池化层 (Subsampling/Pool1): 使用6个$2×2$的采样核。输出特征图大小:$6×14×14$。
原论文中使用平均池化,现代实现常使用最大池化。
- C3卷积层 (Conv2): 使用16个$5×5$的卷积核。输出特征图大小:$16×10×10$,因为$14-5+1=10$。
原始论文中这里使用了复杂的连接表,现代实现通常直接全连接。
- S4池化层 (Subsampling/Pool2): 使用16个$2×2$的采样核。输出特征图大小:$16×5×5$。
- C5卷积层 (Conv3/FC): 使用120个$5×5$的卷积核。输出:120个连接。
这里实际上是一个全连接操作,因为$5×5$的卷积核在$5×5$的输入上操作,结果就是$1×1$。
- F6全连接层 (FullConnection): 输入$120$,输出$84$。
- 输出层 (Output): 高斯连接(现代通常使用SoftMax)。输出10个类别(数字0-9)。

'''2_1'''
class Glue(nn.Module):
"""胶水层,将2维、3维张量转换为4维张量。"""
def forward(self, X_2D):
4个维度依次是BCHW,BatchSize, Channel, Height, Width。
return X_2D.view(-1, 1, 28, 28)
yann_lecun_net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), #⬇⬇ nn.LazyLinear(120),
nn.Linear(400, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10),)
输入必须是4维,BCHW,BatchSize, Channel, Height, Width。
X_4D = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in yann_lecun_net:
X_4D = layer(X_4D)
print(layer.__class__.__name__, "output shape:\t", X_4D.shape)
'''2_2'''
def evaluate_accuracy(votre_modele, iterate_data, device=None):
""""重写评估准确率函数,使用GPU计算。"""
确保isinstance(votre_modele, nn.Module)==True!
votre_modele.eval()
if device is None:
取出模型第一个参数所在的计算设备(cpu|cuda:0|mps:0),输入和权重必须在同一个设备上才能进行运算。
device = next(iter(votre_modele.parameters())).device
2个数,分别是预测正确数、样本总数。
metric = [0.0, 0.0]
for X, y in iterate_data:
确保X是4维张量,而非列表,y是1维张量。
X, y = X.to(device), y.to(device)
metric[0] += Chapter00.count_accurate(votre_modele(X), y)
分类任务中,y.numel()==X.shape[0]都是样本总数。
metric[1] += y.numel()
return metric[0] / metric[1]
'''2_3'''
看一下LeNet在Fashion-MNIST数据集上的表现,batch_size=256。
iterate_devset, iterate_testset = Chapter00.load_data_fashion_mnist(256)
gpu = Chapter01.try_using_gpu()
先把cell2_1的模型定义运行,尤其是含有LazyLinear层。
Chapter01.training_classifier_1on_fashion_mnist(yann_lecun_net, gpu, 10, 0.9,
iterate_devset, iterate_testset, evaluate_accuracy)
保存训练完成的模型的参数。
Chapter01.save_model_(yann_lecun_net, '~/Public/FashionMNIST/model/lecun_net.pth')
'''2_4'''
在Original-MNIST数据集上重新训练LeNet模型。
yann_lecun_net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), #⬇⬇ nn.LazyLinear(120),
nn.Linear(400, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10),)
iterate_devset, iterate_testset = Chapter00.load_data_fashion_mnist(batch_size=256, fashion=False)
gpu = Chapter01.try_using_gpu()
评估准确率函数直接用上面定义好的。
Chapter01.training_classifier_1on_fashion_mnist(yann_lecun_net, gpu, 30, 0.6,
iterate_devset, iterate_testset, evaluate_accuracy)
保存训练完成的模型的参数。
Chapter01.save_model_(yann_lecun_net, '~/Public/MNIST/model/lecun_net.pth')
手写数字识别实验
用已训练好的模型识别自己手写的数字图片看下效果。
'''3_1'''
gpu = Chapter01.try_using_gpu()
yann_lecun_net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), #⬇⬇ nn.LazyLinear(120),
nn.Linear(400, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10),)
Chapter01.load_model_(yann_lecun_net, '~/Public/MNIST/model/lecun_net.pth', gpu)
'''3_2'''
import os
from PIL import Image, ImageOps
from torchvision import transforms
gpu = Chapter01.try_using_gpu()
def process_photo(file_path):
打开图片,并转换为灰度图 (Luminance)。
img = Image.open(file_path).convert('L')
MNIST是黑底白字,如果你的图是白底黑字(常见白纸黑色签字笔),需要反色。
计算图片的平均亮度值,若大于127(偏白),则反色。
if torch.tensor(img.getdata()).float().mean() > 127:
img = ImageOps.invert(img)
简单的门限过滤器,把亮度低于80的全变黑,只保留亮度较高的数字笔画。
hashtab = [0 if i < 100 else i for i in range(256)]
img = img.point(hashtab)
# 获取图片的有效内容的边界框。
bbox = img.getbbox()
# 找到了数字区域,裁剪周边空白的区域。
if bbox:
img = img.crop(bbox)
w, h = img.size
# 按比例缩放图片,使最长边为20px。
a = 20.0 / max(w, h)
# 保持宽高比,防止图像变形。
b, c = int(a * w), int(a * h)
# 使用BILINEAR“双线性插值”,将图片缩放为20❌20。
img = img.resize((b, c), Image.Resampling.BILINEAR)
# 创建一个28❌28的黑色背景。
bgd = Image.new('L', (28, 28), 0)
# 将缩放后的图片粘贴到背景的中心。
bgd.paste(img, ((28 - b) // 2, (28 - c) // 2))
img = bgd
# 定义预处理管道,与训练时一致,将PIL图像转换为torch张量,自动添加通道维度。
megatron = transforms.ToTensor()
# (28, 28) -> (1, 28, 28) -> (1, 1, 28, 28),BCHW,并移到GPU。
X = megatron(img).unsqueeze(0).to(gpu)
# 获取图片文件名,也即真实标签名。
fn = os.path.basename(file_path)
# 去掉扩展名。
y = os.path.splitext(fn)[0]
return X, ydef predict_handwrite(votre_modele, X, y):
"""使用已在OringalMNIST数据集上训练好的模型,对自己手写的数字图片进行预测。"""
评估模式,将张量输入模型,获得预测结果。
votre_modele.eval()
with torch.no_grad():
o = votre_modele(X)
o.shape = (1, 10),就是logits,模型给每个类别打的分。
取出概率最大的类别索引。
p = o.argmax(dim=1).item()
取出该类别概率,置信度。
q = o.softmax(dim=1)0.item()
o.softmax(dim=1)是二维的,[[0.01, 0.02, 0.95, 0.01, ...]]。
print(f"图片{y},预测结果:{p},置信度:{q:.2%},{'对' if p == int(y) else '错'}。")
def traverse_jpgpng(absolute_path:str):
"""遍历指定目录下的所有jpg和png图片,对其进行预测。"""
dire_path = os.path.expanduser(absolute_path)
file_list = os.listdir(dire_path)
file_list.sort()
for fn in file_list:
if not fn.lower().endswith(('.jpg', '.png')):
continue
file_path = os.path.join(dire_path, fn)
X, y = process_photo(file_path)
predict_handwrite(yann_lecun_net, X, y)
'''3_3'''
10张28px❌28px。
traverse_jpgpng('~/Public/MNIST/A_/')
'''3_4'''
10张3024px❌1964px。
traverse_jpgpng('~/Public/MNIST/B_/')
'''3_5'''
10张210mm❌297mm,A4纸大小。
traverse_jpgpng('~/Public/MNIST/C_/')
卷积神经网络可视化
ImageNet
ImageNet是一个由斯坦福大学李飞飞“Fei-Fei Li”教授团队主导的大规模视觉数据库,不仅仅是一个巨大的图片库,它是衡量算法性能的基准,也是现代AI模型预训练的基石。
包含超过1400万张手工标注的图像,涵盖2万多个类别,利用 Amazon Mechanical Turk 众包平台,通过大量人工完成了图片的筛选和边界框标注。常用的是ILSVRC-2012子集,包含128万张开发图片、5万张验证图片、10万张测试图片,1000个类别,平均每张图片尺寸469×387。
Google Gemini & Colab
往后的模型参数量巨大,使用Colab来跑,由Gemini辅助,Drive存储,用同一个账号(treyds765@gmail.com、xluyr786@gmail.com)。并在VSCode中安装Gemini、Colab插件,可以直接在VSCode中使用。
在不需要跑模型的时候一定要关闭,Colab|Runtime|Disconnect and delete runtime。
往后的章节,JupyterKernel选择Colab|NewServer|GPU,起个名enact。
ColabRuntime没有存储功能,想要import自己写的LIMU.py,需要借助GoogleDrive。
import sys
from google.colab import drive, files
drive.mount('/content/drive')
module_path = '/content/drive/MyDrive/ColabNotebooks'
if module_path not in sys.path:
sys.path.append(module_path)
import LIMU
!ls -lah /content/drive/MyDrive/ColabNotebooks
LIMU.py是存储在GoogleDrive上的,挂载去ColabRuntime的路径为/content/drive/MyDrive/ColabNotebooks/LIMU.py,
本来是Colab\ Notebooks,手动重命名为ColabNotebooks,期间需要授权访问GoogleDrive,
如上,就可以将自己写的LIMU模块导入啦。可以下载GoogleDrive桌面应用,实现本地修改,自动同步到云端。
自杀命令,跑完模型后及时关闭,以免浪费。
import time
from google.colab import runtime
time.sleep(5)
print("正在断开运行时以节省资源...")
runtime.unassign()
不过VSCode,Colab扩展似乎不用,它会自动断开。
import torch
print("GPU可用:", torch.cuda.is_available(), torch.cuda.get_device_name(0))
print(f"显存{torch.cuda.get_device_properties(0).total_memory / 1e9:.2f}GB")
开通ColabPro的情况下:
🥇首选推荐T4 经济
GPU型号:Tesla T4,架构:Ada Lovelace,显存15.83GB,自定义别名ant。
🥈进阶推荐L4 中端
GPU型号:NVIDIA L4,架构:Turing,显存23.66GB,自定义别名cat。
🥉备选推荐G4 均衡
GPU型号:NVIDIA RTX PRO 6000,架构:Blackwell,显存101.97GB,自定义别名dog。
A100,架构Ampere,显存40GB,HBM2,全能旗舰。
H100,架构Hopper,显存80GB,HBM3,目前的巅峰。
消耗计算单元太快,太奢侈,不推荐。大炮不打蚊子,效率才是王道。
AlexNet
2012年,在 ImageNet Large Scale Visual Recognition Challenge 上以压倒性的优势夺冠,标志着深度学习在计算机视觉领域的统治地位正式确立。由Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton合作设计。
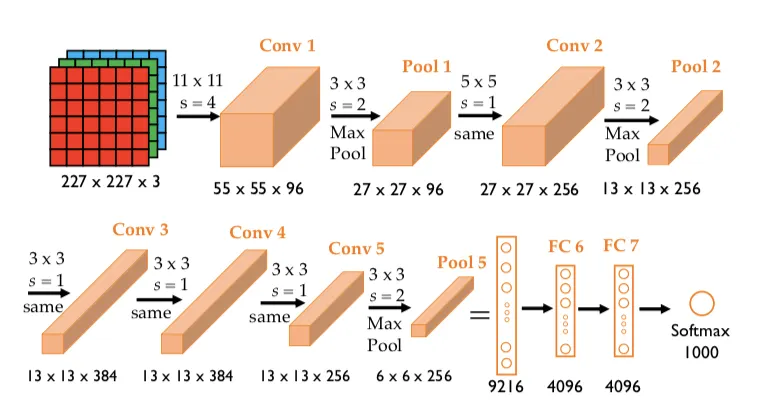
'''4_1'''
我们将使用Fashion-MNIST来训练我们的AlexNet,而非ImageNet,所以这里
第一层输入通道是1,不是论文中的3,对应Fashion-MNIST的灰度图。
最后输出是10,不是论文中的1000,对应Fashion-MNIST的10类别。
alex_krizh_net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 10))
输入必须是4维,BCHW,BatchSize, Channel, Height, Width。
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for layer in alex_krizh_net:
X_4D = layer(X_4D)
print(layer.__class__.__name__, "output shape:\t", X_4D.shape)
'''4_2'''
gpu = Chapter01.try_using_gpu()
用ImageNet训练模型成本太大了,我们仍使用Fashion-MNIST。
首先要将Fashion-MNIST的28❌28图像,放大到224❌224。
iterate_devset, iterate_testset = Chapter00.load_data_fashion_mnist(32, 224)
训练模型,不要用笔记本跑,风扇狂转,耗时很久,顶不住!超参数调小了勉强跑一下。
Chapter01.training_classifier_1on_fashion_mnist(
alex_krizh_net, gpu, 3, 0.1, iterate_devset, iterate_testset)
上面是在MacBook上跑了一下AlexNet,可以看出性能不太行。
