%%HTML
'''0_0'''
import matplotlib.pyplot as plt
import numpy as np
import time
import torch
from IPython import display
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
%config InlineBackend.figure_format = 'svg'
gpu = torch.device("cuda:0")
gpu = torch.device("mps:0")
'''0_1'''
print(f"GPU个数:{torch.cuda.device_count()},PyTorch版本:{torch.__version__}。")
print(f"GPU型号:{torch.cuda.get_device_name(0)},显存{torch.cuda.get_device_properties(0).total_memory / 1e9:.2f}GB。")
Colab中文显示问题,文泉驿微米黑开源中文字体。
!sudo apt-get install -y fonts-wqy-microhei
!rm -rf ~/.cache/matplotlib
from matplotlib import font_manager
font_manager.fontManager.addfont('/usr/share/fonts/truetype/wqy/wqy-microhei.ttc')
Colab不方便使用自己写的.py,将LIMU.py全放下面了,不过,做了些裁剪。
'''0_2'''
'''------------------------------辅助类------------------------------'''
class ZigzagChartAnimator:
"""折线图动画可视化类。"""
def __init__(self, title='', legend=(), info_xy_=('','',(),(),'linear','linear'),
rows=1, cols=1, figsize=(5, 2.5)):
"""
title: 图表标题
legend: 图例列表
info_xy_: 包含x轴和y轴共6个参数
xlabel: x轴标签 -字符串
ylabel: y轴标签 -字符串
xlimit: x轴范围 -元组含2个数 空元组自动匹配数据范围
ylimit: y轴范围 -元组含2个数 空元组自动匹配数据范围
xscale: x轴缩放 -可选('linear', 'log')
yscale: y轴缩放 -可选('linear', 'log')
rows: 子图行数
cols: 子图列数
figsize: 图表尺寸
"""
正常显示中文字符,和负号。
plt.rcParams['font.sans-serif'] = ['WenQuanYi Micro Hei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 创建子图网格。
self.fig, self.axes = plt.subplots(rows, cols, figsize=figsize)
# self.fig.canvas.manager.set_window_title(title)
if rows * cols == 1:
# 如果只有1个子图,返回的是1个Axes对象,转为列表。
self.axes = [self.axes]
# 通过lambda函数的闭包机制捕获所有必要的上下文信息。
self.config_axes = lambda: self._set_axes(self.axes[0], title, legend, info_xy_)
# m: 要绘多少条线。
m = len(legend)
self.X_2dli = [[] for _ in range(m)]
self.Y_2dli = [[] for _ in range(m)]
def _set_axes(self, ax, title, legend, info_xy_):
"""
ax: 子图Axes对象
title: 图表标题
legend: 图例列表
xlabel: x轴标签
ylabel: y轴标签
xlimit: x轴范围
ylimit: y轴范围
xscale: x轴缩放
yscale: y轴缩放
"""
xlabel, ylabel, xlimit, ylimit, xscale, yscale = info_xy_
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
if xlimit:
ax.set_xlim(xlimit)
if ylimit:
ax.set_ylim(ylimit)
ax.set_xscale(xscale)
ax.set_yscale(yscale)
# 图例锚点(1.0, 0.7),距离画布右下角(100%, 70%)位置处,图例框的'lower left'钉在锚点。
ax.legend(legend, loc='lower left', bbox_to_anchor=(1.0, 0.7))
ax.set_title(title)
ax.grid(True)
def insert_point(self, x_li, y_li, ipy=True):
"""
向折线图中添加数据点
x_li: x坐标值 可以是数或列表
y_li: y坐标值 可以是数或列表
普通Python环境在所有insert_point()之后一定要加一行plt.show(),显示最终图表!
"""
if not hasattr(y_li, "__len__"):
# 数,转列表,方便后续遍历。
y_li = [y_li]
m = len(y_li)
if not hasattr(x_li, "__len__"):
# 数,转列表,方便后续遍历。
x_li = [x_li] * m
# 比如x_li=1, y_li=[0.2,0.3,0.4],转换成[1,1,1], [0.2,0.3,0.4]。
# 即1个横坐标对应3个纵坐标,3条线。
# 添加数据点。
for i, (a, b) in enumerate(zip(x_li, y_li)):
if a and b:
# a, b 都是数。
self.X_2dli[i].append(a)
self.Y_2dli[i].append(b)
# 清除当前图表并重新绘制。
self.axes[0].clear()
# 定义线条样式,依次顺序使用下面元素。
fmts = ('-','m--','g-.','r:','y-o','k-v','w-x')
for x_li, y_li, t in zip(self.X_2dli, self.Y_2dli, fmts):
self.axes[0].plot(x_li, y_li, t)
# 重新配置坐标轴。
self.config_axes()
self._show_plot(ipy)
def _show_plot(self, ipy=True):
"""显示图表。"""
# iPython、Jupyter场景如下方式。
if ipy:
# 显示图形并清空之前的输出。
display.display(self.fig)
display.clear_output(wait=True)
# 普通Python场景如下方式。
else:
# 强制重绘图表并短暂暂停程序执行,以便用户查看。
plt.draw()
plt.pause(0.5)
# 在所有add_point()之后,再加一行plt.show(),显示最终图表!class StopWatchMonitor:
"""记录代码多次运行的相关时间。"""
def __init__(self):
秒数记录列表。
self.secos_list = []
self.start()
def __enter__(self):
"""支持上下文管理器。"""
self.start()
return self
def __exit__(self, *args):
"""退出上下文时自动停止计时。"""
self.stop()
def start(self):
"""启动秒表监视器。"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中。"""
self.secos_list.append(time.time() - self.tik)
return self.secos_list[-1]
def sum(self):
"""返回时间总和。"""
return sum(self.secos_list)
def avg(self):
"""返回平均耗时。"""
return sum(self.secos_list) / len(self.secos_list)
def cml(self):
"""返回时间叠加和,CumulativeSum,就是PrefixSum前缀和。"""
return np.array(self.secos_list).cumsum().tolist()'''------------------------------章节类------------------------------'''
class Chapter00:
@staticmethod
def load_data_fashion_mnist(batch_size, reset_size=None, fashion=True):
"""
默认加载Fashion-MNIST数据集到内存里。
参数:
batch_size: 批量大小,通常取256。
reset_size: 可选,图像重置尺寸,数或元组,例如32、(16, 9)。
fashion: True,Fashion-MNIST;False,Original-MNIST。
返回:
iterate_devset: @torch.utils.data.DataLoader,开发数据集迭代器,60000个样本。
iterate_testset: @torch.utils.data.DataLoader,测试数据集迭代器,10000个样本。
"""
if reset_size:
megatron = transforms.Compose([
transforms.Resize(reset_size), transforms.ToTensor()])
else:
megatron = transforms.Compose([transforms.ToTensor()])
# megatron来自《变形金刚transformers》里的“威震天”。
# optimus_prime“擎天柱”,bumblebee“大黄蜂”。
root_dir = "/content/drive/MyDrive/ColabNotebooks"
if fashion:
fashion_mnist_dev = datasets.FashionMNIST(
root=root_dir, train=True, transform=megatron, download=True)
fashion_mnist_test = datasets.FashionMNIST(
root=root_dir, train=False, transform=megatron, download=True)
else:
fashion_mnist_dev = datasets.MNIST(
root=root_dir, train=True, transform=megatron, download=True)
fashion_mnist_test = datasets.MNIST(
root=root_dir, train=False, transform=megatron, download=True)
# MacBookARM64平台,使用MPS后端,多进程在共享内存方面存在兼容性问题,num_workers=0是当前最稳妥的选择,创建0个子进程。
return (DataLoader(fashion_mnist_dev, batch_size, shuffle=True, num_workers=0),
DataLoader(fashion_mnist_test, batch_size, shuffle=False, num_workers=0))
@staticmethod
def count_accurate(o, y):
"""
计算预测正确的数量。
参数:
o: 模型预测输出,形状为(batch_size, num_classes)。
y: 真实标签,形状为(batch_size,)。
返回:
预测正确的数量,转浮点数。
"""
if len(o.shape) > 1 and o.shape[1] > 1:
# 若o是多维的,且第2维大于1,则对每个样本取最大概率的类别索引,即下标。
o = o.argmax(axis=1)
# 创建bool张量,标记哪些预测正确。
comp = o.type(y.dtype) == y
# True→1,False→0,求和。
return float(comp.type(y.dtype).sum())class Chapter01:
@staticmethod
def init_weights(mo):
"""初始化权重。"""
if isinstance(mo, nn.Linear) or isinstance(mo, nn.Conv2d):
nn.init.xavier_uniform_(mo.weight)
@staticmethod
def evaluate_accuracy(votre_modele, iterate_data, device=None):
""""评估准确率函数,使用GPU计算。"""
# 确保isinstance(votre_modele, nn.Module)==True!
votre_modele.eval()
if device is None:
# 取出模型第一个参数所在的计算设备(cpu|cuda:0|mps:0),输入和权重必须在同一个设备上才能进行运算。
device = next(iter(votre_modele.parameters())).device
# 2个数,分别是预测正确数、样本总数。
metric = [0.0, 0.0]
for XX, y in iterate_data:
if isinstance(XX, list):
# 支持多输入,例如BERT。
X = [X.to(device) for X in XX]
else:
X = XX.to(device)
y = y.to(device)
metric[0] += Chapter00.count_accurate(votre_modele(X), y)
# 分类任务中,y.numel()==X.shape[0]都是样本总数。
metric[1] += y.numel()
return metric[0] / metric[1]
@staticmethod
def training_classifier_1on_fashion_mnist(votre_modele:nn.Module,
device:torch.device, train_epochs:int, learning_rate:float,
iterate_devset, iterate_testset, evaluate_accuracy=evaluate_accuracy):
"""
训练分类器。
参数:
votre_modele: 你的模型,使用torch.nn.Module内置的。
train_epochs: 训练轮数、超参数。
learning_rate: 学习率、超参数。
iterate_devset: @torch.utils.data.DataLoader,开发数据集迭代器。
iterate_testset: @torch.utils.data.DataLoader,测试数据集迭代器。
evaluate_accuracy: 评估准确率的函数。
loss_function, train_optimizer就使用torch框架提供的啦。
返回:
无,绘制折线图使训练过程可视化,包含损失值、开发数据集准确率、测试数据集准确率。
"""
votre_modele.apply(Chapter01.init_weights)
votre_modele.to(device)
train_optimizer = optim.SGD(votre_modele.parameters(), lr=learning_rate)
# 使用默认的reduction='mean',返回每个批次样本的平均损失,梯度也是平均梯度。
loss_function = nn.CrossEntropyLoss()
# 批次总数量,开发数据集60000个样本,批次大小取256,ceil(60000/256)=235个批次,最后一次批次只有96个样本。
numof_batches = len(iterate_devset)
info_xy_ = ("训练轮数","",(1,train_epochs),None,'linear','linear')
animator = ZigzagChartAnimator('训练过程可视化', ['损失值', '开发数据集准确率', '测试数据集准确率'], info_xy_)
monitor = StopWatchMonitor()
for epoch in range(train_epochs):
# 3个数,分别是损失总和、预测正确数、样本总数。
metric = [0.0, 0.0, 0.0]
votre_modele.train()
for i, (X, y) in enumerate(iterate_devset):
monitor.start()
train_optimizer.zero_grad()
X, y = X.to(device), y.to(device)
# o是logits,生数据,没有经过softmax归一化。
o = votre_modele(X)
CE = loss_function(o, y)
CE.backward()
train_optimizer.step()
# 防御性编程Safety。
with torch.no_grad():
metric[0] += CE.item() * y.numel()
metric[1] += Chapter00.count_accurate(o, y)
# 分类任务中,y.numel()==X.shape[0]都是样本总数。
# 若是语义分割、独热编码,y.numel()是类别总数、像素总数,则!=X.shape[0]。
metric[2] += y.numel()
monitor.stop()
train_loss, train_accu = metric[0] / metric[2], metric[1] / metric[2]
# 把一个epoch分成5份,当前迭代刚好走完了1份(进度条20%、40%、60%、80%、100%)时,描点。
if (i + 1) % (numof_batches // 5) == 0 or (i + 1) == numof_batches:
animator.insert_point(epoch + (i + 1) / numof_batches,
[train_loss, train_accu, None])
# 看一下评估模式在测试数据集上的准确率。
infer_accu = evaluate_accuracy(votre_modele, iterate_testset)
animator.insert_point(epoch + 1, [None, None, infer_accu])
print(f"完成,损失值:{train_loss:.3f},开发数据集准确率:{train_accu:.3f},测试数据集准确率:{infer_accu:.3f}。")
print(f"在{device}上计时{monitor.sum():.2f}秒,每秒{metric[2] * train_epochs / monitor.sum():.1f}个样本。")'''1_2'''
要将Fashion-MNIST的28❌28图像,放大到224❌224,批次大小128。
iterate_devset, iterate_testset = Chapter00.load_data_fashion_mnist(128, 224)
现代卷积神经网络
CNN Convolutional Neural Network
AlexNet
2012年,在 ImageNet Large Scale Visual Recognition Challenge 上以压倒性的优势夺冠,标志着深度学习在计算机视觉领域的统治地位正式确立。由Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton合作设计。
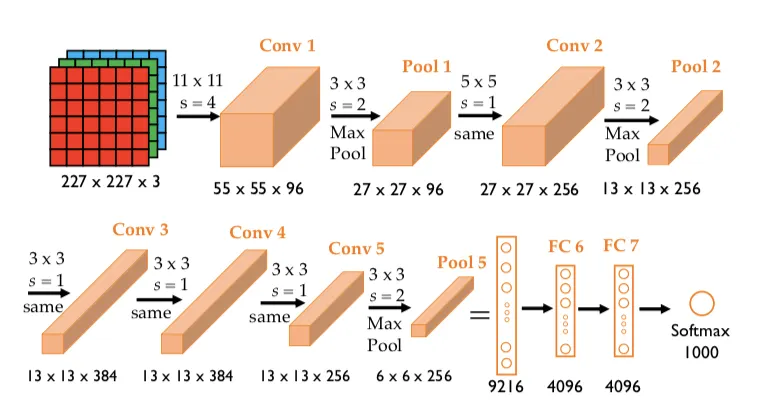
'''1_1'''
我们将使用Fashion-MNIST来训练我们的AlexNet,而非ImageNet,所以这里
第一层输入通道是1,不是论文中的3,对应Fashion-MNIST的灰度图。
最后输出是10,不是论文中的1000,对应Fashion-MNIST的10类别。
alex_krizh_net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 10))
输入必须是4维,BCHW,BatchSize, Channel, Height, Width。
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for layer in alex_krizh_net:
X_4D = layer(X_4D)
print(f"{layer.__class__.__name__:>20} output shape:\t{X_4D.shape}")
'''1_2'''
Chapter01.training_classifier_1on_fashion_mnist(
alex_krizh_net, gpu, 10, 0.1, iterate_devset, iterate_testset)
VGG块
VGG块是由牛津大学视觉几何组 Visual Geometry Group 提出的核心构建单元。论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》,作者Karen Simonyan、Andrew Zisserman。在2014年的ImageNet竞赛中获亚军。
简单来说,VGG块的设计思想就是:用多个小的$3×3$卷积层堆叠(步长1,填充1,),来替代一个大的卷积层,2个堆叠的$3×3$卷积层的感受野相当于1个$5×5$的卷积层,3个堆叠的$3×3$卷积层的感受野相当于1个$7×7$的卷积层,使用多个小卷积核代替一个大卷积核,可以在保持相同感受野 "Receptive Field" 的同时,减少参数量,并引入更多的非线性激活函数(ReLU),从而增强网络的判别能力。通过堆叠这些卷积块,VGG成功地将网络深度推到了16层(VGG16)、19层(VGG19)。
后面跟池化层, 使用$2×2$的最大池化,步长为2,用于减小特征图的尺寸。
2个堆叠的$3×3$卷积层,看宽度一维方向,输入层经过第1层卷积得到中间层1,中间层1经过第2层卷积得到输出层,假设输出点在位置$i$:
- 输出层 $i$ 依赖于 中间层1 的 $[i-1,i,i+1]$。
- 中间层1 $i-1$ 依赖于 输入层 的 $[(i-1)-1,(i-1),(i-1)+1] = [i-2,i-1,i]$。
- 中间层1 $i+1$ 依赖于 输入层 的 $[(i+1)-1,(i+1),(i+1)+1] = [i,i+1,i+2]$。
取并集,输出层 的1个像素点取决于 输入层 的 $[i-2,...,i+2]$ ,5个点,感受野就是5。
而参数量是 $2×3×3×C_{in}×C_{out}=18C^2$ ,换作1个$5×5$的卷积层的话参数量是 $5×5×C_{in}×C_{out}=25C^2$ 。
非线性增强:
1个$5×5$卷积层后面通常只接1个非线性激活函数,如ReLU。2个堆叠的$3×3$卷积层,中间可以插入2个ReLU。更多的非线性层使得网络能学习更复杂的特征函数。
'''2_1'''
def vgg_blk(num_convs, chann_in, chann_out):
"""VGG块,包含num_convs个卷积层,输入通道数chann_in,输出通道数chann_out。"""
the_layers = []
for _ in range(num_convs):
the_layers.append(nn.Conv2d(chann_in, chann_out,
kernel_size=3, padding=1))
the_layers.append(nn.ReLU())
chann_in = chann_out
the_layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*the_layers)
def vgg_net(conv_arch):
"""VGG网络,vgg块的架构由conv_arch指定。"""
blk_list = []
chann_in = 1
for num_convs, chann_out in conv_arch:
blk_list.append(vgg_blk(num_convs, chann_in, chann_out))
chann_in = chann_out
blk_list.extend([nn.Flatten(), nn.Linear(512 7 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 10)])
return nn.Sequential(*blk_list)
'''2_2'''
包含5个VGG块,卷积层个数依次是1、1、2、2、2,输出通道数依次是64、128、256、512、512。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
卷积层1+1+2+2+2=8个,全连接层3个,总共11个。
vgg_blk_net_11 = vgg_net(conv_arch)
输入必须是4维,BCHW,BatchSize, Channel, Height, Width。
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for block in vgg_blk_net_11:
X_4D = block(X_4D)
print(f"{block.__class__.__name__:>20} output shape:\t{X_4D.shape}")
'''2_3'''
Chapter01.training_classifier_1on_fashion_mnist(
vgg_blk_net_11, gpu, 10, 0.1, iterate_devset, iterate_testset)
'''2_4'''
conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))
卷积层13个,全连接层3个。
vgg_blk_net_16 = vgg_net(conv_arch)
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for block in vgg_blk_net_16:
X_4D = block(X_4D)
print(f"{block.__class__.__name__:>20} output shape:\t{X_4D.shape}")
'''2_5'''
看下VGG-16效果怎么样。
Chapter01.training_classifier_1on_fashion_mnist(
vgg_blk_net_16, gpu, 10, 0.1, iterate_devset, iterate_testset)
耗时巨长,Colab T4 耗时154分,准确率还低。
NiN块
NiN是由新加坡国立大学的【林敏、陈强、颜水成】在2013年的论文《Network In Network》中提出的一种深度学习网络架构。它虽然没有像AlexNet或VGG那样因赢得ImageNet竞赛而一举成名,但它提出的两个核心思想 —— MLP Convolution Layer 和 Global Average Pooling——对后来的卷积神经网络设计产生了极其深远的影响,例如GoogLeNet、ResNet都借鉴了其思想。可以把NiN看作是连接传统CNN和现代CNN的一座重要桥梁。
- MLP Convolution Layer
传统CNN的问题:在传统的卷积层中,滤波器是线性的。它对感受野内的数据进行加权求和,然后通过一个非线性激活函数。这种线性模型对于提取高度非线性的抽象特征能力有限。作者认为,要提取更抽象的特征,需要更强大的函数逼近器。
NiN的解决方案:NiN提出用一个微型网络来替代传统的线性滤波器。这个微型网络本身就是一个小型的多层感知机(MLP)。具体来说,它由多个$1×1$的卷积层堆叠而成。
- 一个$1×1$的卷积可以看作是对输入特征图 "feature map" 的每个像素位置上的所有通道进行一次全连接操作。
- 将多个$1×1$卷积层和激活函数堆叠起来,就构成了一个小型的MLP,它能够对感受野内的特征进行更复杂的非线性变换和抽象。
- Global Average Pooling
传统CNN的问题:在NiN之前,CNN的末端通常会接上几个全连接层来进行分类。这些全连接层存在几个严重问题:1️⃣参数量巨大,例如AlexNet中90%的参数都集中在全连接层;2️⃣可解释性差,全连接层像一个“黑盒”,它破坏了卷积层输出特征图的空间信息,使得我们很难将最终的分类结果与原始图像的特定区域联系起来。
NiN的解决方案:NiN提出用全局平均池化(GAP)层来取代全连接层。
- 在网络的最后一个Mlpconv层,假设我们得到了$C$个特征图,GAP层对每一个特征图计算其所有像素值的平均值。这样,一个$H×W$大小的特征图就被池化成一个单一的数值。
- $C$个特征图就得到了一个长度为$C$的向量,这个向量直接被送入Softmax层进行分类。
'''3_1'''
def nin_blk(chann_in, chann_out, kernel_size, stride, padding):
"""NiN块,包含3个卷积层,输入通道数chann_in,输出通道数chann_out。"""
the_layers = [nn.Conv2d(chann_in, chann_out, kernel_size, stride, padding), nn.ReLU(),
nn.Conv2d(chann_out, chann_out, kernel_size=1), nn.ReLU(),
nn.Conv2d(chann_out, chann_out, kernel_size=1), nn.ReLU()]
return nn.Sequential(*the_layers)
def nin_net():
"""NiN网络,nin块的架构固定。"""
return nn.Sequential(
第1个NiN块,输入通道数1,输出通道数96,卷积核大小11,步幅4,填充0。
nin_blk(1, 96, kernel_size=11, stride=4, padding=0),
nn.MaxPool2d(kernel_size=3, stride=2),
第2个NiN块,输入通道数96,输出通道数256,卷积核大小5,步幅1,填充2。
nin_blk(96, 256, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=3, stride=2),
第3个NiN块,输入通道数256,输出通道数384,卷积核大小3,步幅1,填充1。
nin_blk(256, 384, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
第4个NiN块,输入通道数384,输出通道数10,卷积核大小3,步幅1,填充1。
nin_blk(384, 10, kernel_size=3, stride=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten())
'''3_2'''
nin_blk_net_4 = nin_net()
输入必须是4维,BCHW,BatchSize, Channel, Height, Width。
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for block in nin_blk_net_4:
X_4D = block(X_4D)
print(f"{block.__class__.__name__:>20} output shape:\t{X_4D.shape}")
'''3_3'''
Chapter01.training_classifier_1on_fashion_mnist(
nin_blk_net_4, gpu, 10, 0.1, iterate_devset, iterate_testset)
GoogLeNet
也称为 Inception v1,在2014年的ImageNet竞赛中获得了冠军。主要贡献者是Google的研究团队的 Christian Szegedy 等人,GoogLe也是为了致敬LeNet。
- 核心创新:Inception模块
在GoogLeNet之前,设计卷积神经网络面临一个两难的选择:卷积核选多大?$1×1$?$3×3$?还是$5×5$?
小的卷积核能捕捉局部细节。大的卷积核能捕捉更宏观的特征。Inception模块的解决方案是:我全都要。
它在一个层级内并行使用多种尺寸的卷积核,然后将结果拼接 "Concatenate" 在一起。
关键技术:$1×1$卷积 (Bottleneck Layer “瓶颈层”)
如果直接并行堆叠$3×3$和$5×5$的卷积,计算量会爆炸。GoogLeNet引入了$1×1$卷积来进行降维 "Dimensionality Reduction"。
在进入昂贵的$3×3$或$5×5$卷积之前,先通过$1×1$卷积减少通道数。这不仅减少了参数,还增加了网络的非线性(因为每个卷积后都有ReLU)。

- 网络架构特点
深度:网络共有22层(带参数的层),比当时的VGG网络更深。
参数量少:GoogLeNet的参数量约为400~500万个,而同期的VGG-16参数量高达1.38亿个。GoogLeNet更加轻量级。
去除了全连接层 "No FC Layers":在网络的末端,GoogLeNet使用全局平均池化层来替代传统的全连接层。这极大地减少了参数量,并防止了过拟合。
辅助分类器 "Auxiliary Classifiers":为了解决深层网络中的梯度消失 "Vanishing Gradient" 问题,GoogLeNet在网络的中间部分引出了两个额外的分支作为辅助分类器。
- 后续演进
Inception v2/v3 :引入Batch Normalization,并将$5×5$卷积分解为2个$3×3$卷积,甚至分解为$1×7$和$7×1$的非对称卷积,进一步降低计算量。
Inception v4 :结合了ResNet的残差连接思想,使得网络训练更加稳定,收敛更快。
'''4_1'''
class Inception(nn.Module):
"""下面定义的是Inception v1。"""
def __init__(self, chann_in, chann_out1, chann_out2, chann_out3, chann_out4, version=1):
super().__init__()
self.version = version
线路route1,1×1卷积层。
self.rt1 = nn.Sequential(nn.Conv2d(chann_in, chann_out1, kernel_size=1), nn.ReLU())
线路route2,1×1卷积层、3×3卷积层。
self.rt2 = nn.Sequential(nn.Conv2d(chann_in, chann_out2[0], kernel_size=1), nn.ReLU(),
nn.Conv2d(chann_out2[0], chann_out2[1], kernel_size=3, padding=1), nn.ReLU())
线路route3,1×1卷积层、5×5卷积层。
self.rt3 = nn.Sequential(nn.Conv2d(chann_in, chann_out3[0], kernel_size=1), nn.ReLU(),
nn.Conv2d(chann_out3[0], chann_out3[1], kernel_size=5, padding=2), nn.ReLU())
线路route4,3×3最大池化层、1×1卷积层。
self.rt4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(chann_in, chann_out4, kernel_size=1), nn.ReLU())
def forward(self, X_4D):
# 线路route1,1×1卷积层。
rt1 = self.rt1(X_4D)
# 线路route2,1×1卷积层、3×3卷积层。
rt2 = self.rt2(X_4D)
# 线路route3,1×1卷积层、5×5卷积层。
rt3 = self.rt3(X_4D)
# 线路route4,3×3最大池化层、1×1卷积层。
rt4 = self.rt4(X_4D)
# BCHW,在通道维度上连结输出,总通道数=chann_out1+chann_out2[1]+chann_out3[1]+chann_out4。
return torch.cat((rt1, rt2, rt3, rt4), dim=1)'''4_2'''
class GoogLeNet(nn.Module):
def __init__(self):
super().__init__()
第1阶段,64×7×7卷积层、3×3最大池化层,主要目的是快速降低分辨率。
self.stage1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第2阶段,64×1×1卷积层、192×3×3卷积层、3×3最大池化层,提取低级特征。
self.stage2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第3阶段,2个Inception块、3×3最大池化层。
self.stage3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第4阶段,躯干,5个Inception块、3×3最大池化层。
self.stage4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第5阶段,2个Inception块、全局平均池化层。
self.stage5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)), nn.Flatten())
全连接层,输出10个分类的logits,再传给Softmax。
self.fc = nn.Linear(1024, 10)
def forward(self, X_4D):
X_4D = self.stage1(X_4D)
X_4D = self.stage2(X_4D)
X_4D = self.stage3(X_4D)
X_4D = self.stage4(X_4D)
X_4D = self.stage5(X_4D)
return self.fc(X_4D)'''4_3'''
chris_szeg_net = GoogLeNet()
输入必须是4维,BCHW,BatchSize, Channel, Height, Width。
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for block in chris_szeg_net.children():
X_4D = block(X_4D)
print(f"{block.__class__.__name__:>20} output shape:\t{X_4D.shape}")
'''4_4'''
Chapter01.training_classifier_1on_fashion_mnist(
chris_szeg_net, gpu, 10, 0.1, iterate_devset, iterate_testset)
批量规一化
Batch Normalization,Google团队 Ioffe、Szegedy 在2015年提出。
问题提出:神经网络中,损失出现在靠近输出的后面层,后面层梯度大学习较快,由梯度的反向传播,靠近输入的前面层梯度小学习较慢。而前面层是提取低级特征的,前面层一变后面层要重新学习,导致神经网络收敛很慢。如何在前面层学习的同时避免后面层的重新学习?
核心思想:针对每批次的样本,在进入激活函数之前,强行将其拉回到标准正态分布,然后再通过2个可学习的参数进行缩放和平移,以保留模型的表达能力。
数学步骤:
- 当前批次样本$x$,形状是$BCHW$。
- 按通道计算样本的均值$𝜇$和方差$𝜎^2$。
- 归一化,$\hat{x}=\frac{x-𝜇}{\sqrt{𝜎^2+𝜀}}$,加𝜀是为了防止分母为0。
- 缩放和平移,$y=𝛾\hat{x}+𝛽$。
举个例子:
假设我们的$BCHW=(2,2,2,2)$,即2张图片(A、B),每张图片2个通道,图片极小宽2px高2px。
输入$x$
图片A: 通道0 $[[0,0],[0,0]]$ 通道1 $[[2,2],[2,2]]$
图片B: 通道0 $[[10,10],[10,10]]$ 通道1 $[[4,4],[4,4]]$
通道0,数据池$[0,0,0,0,10,10,10,10]$。
- 计算均值和方差
$𝜇_0=\frac{0×4+10×4}{8}=5,𝜎^2_0=\frac{25×4+25×4}{8}=25,𝜎=5.$。 - 归一化
图片A,$(0-5)/5=-1$,4个像素值变成$[[-1,-1],[-1,-1]]$。
图片B,$(10-5)/5=1$,4个像素值变成$[[1,1],[1,1]]$。
通道1,数据池$[2,2,2,2,4,4,4,4]$。
- 计算均值和方差
$𝜇_1=\frac{2×4+4×4}{8}=3,𝜎^2_1=\frac{1×4+1×4}{8}=1,𝜎=1.$。 - 归一化
图片A,$(2-3)/1=-1$,4个像素值变成$[[-1,-1],[-1,-1]]$。
图片B,$(4-3)/1=1$,4个像素值变成$[[1,1],[1,1]]$。
暂时忽略了归一化时,分母上的极小数𝜀。
中间值$\hat{x}$
图片A: 通道0 $[[-1,-1],[-1,-1]]$ 通道1 $[[-1,-1],[-1,-1]]$
图片B: 通道0 $[[1,1],[1,1]]$ 通道1 $[[1,1],[1,1]]$
注意观察:两张图片虽然通道0的输入值差距很大 (0、10),通道1的输入值差距很小 (2、4),但经过BN后,它们都变成了$-1,1$。
缩放和平移,也是按通道处理,假设神经网络已经学习好缩放和平移的参数。
通道0,缩放$𝛾_0=2$,平移$𝛽_0=10$,意图把数据拉大并整体抬高。
通道1,缩放$𝛾_1=0.5$,平移$𝛽_1=1$,意图把数据缩小并微调位置。
输出$y$
图片A: 通道0 $[[8.0,8.0],[8.0,8.0]]$ 通道1 $[[0.5,0.5],[0.5,0.5]]$
图片B: 通道0 $[[12.0,12.0],[12.0,12.0]]$ 通道1 $[[1.5,1.5],[1.5,1.5]]$
虽然都是从$-1,1$变过来的,但不同通道的𝛾、𝛽不同,最终的数值范围完全不同了,这就是BN层赋予网络的灵活性。
'''5_1'''
def batch_norm(X, gamma, beta, epsilon, moving_mean, moving_var, momentum):
"""批量归一化计算的手动实现。"""
if not torch.is_grad_enabled():
评估模式,直接使用移动平均所得的均值和方差。
X_hat = (X - moving_mean) / torch.sqrt(moving_var + epsilon)
else:
训练模式,使用当前批次的均值和方差,并更新移动平均的均值和方差。
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
全连接层的批量归一化,计算特征维上的均值和方差。
进入全连接层前的数据通常被Flatten成二维的(N,F)批次大小、特征。
可以不写keepdim=True,形状为(F,),pytorch会从右到左广播,沿着N维度复制。
still_mean = X.mean(dim=0)
still_var = ((X - still_mean) ** 2).mean(dim=0)
else:
卷积层的批量归一化,计算通道维上的均值和方差,保持维度以便后续广播。
如果keepdim=False,形状为(C,),无法与形状为(N,C,H,W)的X做减法。
keepdim=True,形状为(1,C,1,1),N,H,W维度上可以广播。
still_mean = X.mean(dim=(0, 2, 3), keepdim=True)
still_var = ((X - still_mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
X_hat = (X - still_mean) / torch.sqrt(still_var + epsilon)
更新移动平均的均值和方差,指数移动平均,历史数据的动量因子会越乘越小。
moving_mean = momentum moving_mean + (1.0 - momentum) still_mean
moving_var = momentum moving_var + (1.0 - momentum) still_var
缩放和移位,gamma和beta是可学习参数,形状与X的特征维或通道维相同,保持维度以便后续广播。
Y = gamma * X_hat + beta
return Y, moving_mean.data, moving_var.data
'''5_2'''
class Consecutive2d(nn.Module):
"""包装卷积层->批量归一化层->激活函数,连续进行的基本模块,可以避免在Inception块中写重复代码。"""
def __init__(self, chann_in, chann_out, **kwargs):
super().__init__()
BN层已有beta,卷积层就不需要偏置了,bias=False。
self.conv = nn.Conv2d(chann_in, chann_out, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(chann_out)
self.relu = nn.ReLU(inplace=True)
def forward(self, X_4D):
X_4D = self.conv(X_4D)
X_4D = self.bn(X_4D)
X_4D = self.relu(X_4D)
return X_4D'''5_3'''
class Inception(nn.Module):
"""Inception v1基础上添加了批量归一化。"""
def __init__(self, chann_in, chann_out1, chann_out2, chann_out3, chann_out4):
super().__init__()
线路route1,1×1卷积层。
self.rt1 = Consecutive2d(chann_in, chann_out1, kernel_size=1)
线路route2,1×1卷积层、3×3卷积层。
self.rt2 = nn.Sequential(Consecutive2d(chann_in, chann_out2[0], kernel_size=1),
Consecutive2d(chann_out2[0], chann_out2[1], kernel_size=3, padding=1))
线路route3,1×1卷积层、5×5卷积层。
self.rt3 = nn.Sequential(Consecutive2d(chann_in, chann_out3[0], kernel_size=1),
Consecutive2d(chann_out3[0], chann_out3[1], kernel_size=5, padding=2))
线路route4,3×3最大池化层、1×1卷积层。
self.rt4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
Consecutive2d(chann_in, chann_out4, kernel_size=1))
def forward(self, X_4D):
rt1 = self.rt1(X_4D)
rt2 = self.rt2(X_4D)
rt3 = self.rt3(X_4D)
rt4 = self.rt4(X_4D)
return torch.cat((rt1, rt2, rt3, rt4), dim=1)'''5_4'''
class GoogSeNet(nn.Module):
"""将BatchNorm层集成到GoogLeNet中。"""
def __init__(self):
super().__init__()
第1阶段,64×7×7卷积层、3×3最大池化层,主要目的是快速降低分辨率。
self.stage1 = nn.Sequential(Consecutive2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第2阶段,64×1×1卷积层、192×3×3卷积层、3×3最大池化层,提取低级特征。
self.stage2 = nn.Sequential(Consecutive2d(64, 64, kernel_size=1),
Consecutive2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第3阶段,2个Inception块、3×3最大池化层。
self.stage3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第4阶段,躯干,5个Inception块、3×3最大池化层。
self.stage4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第5阶段,2个Inception块、全局平均池化层。
self.stage5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)), nn.Flatten())
全连接层,输出10个分类的logits,再传给Softmax。
self.fc = nn.Linear(1024, 10)
def forward(self, X_4D):
X_4D = self.stage1(X_4D)
X_4D = self.stage2(X_4D)
X_4D = self.stage3(X_4D)
X_4D = self.stage4(X_4D)
X_4D = self.stage5(X_4D)
return self.fc(X_4D)'''5_5'''
chris_szeg_net = GoogLeNet()
输入必须是4维,BCHW,BatchSize, Channel, Height, Width。
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for block in chris_szeg_net.children():
X_4D = block(X_4D)
print(f"{block.__class__.__name__:>20} output shape:\t{X_4D.shape}")
'''5_6'''
Chapter01.training_classifier_1on_fashion_mnist(
chris_szeg_net, gpu, 10, 0.1, iterate_devset, iterate_testset)
ResNet
Residual Network,残差神经网络。计算机视觉领域的一个里程碑式模型,由何恺明(Kaiming He)等人在2015年提出,在当年的ILSVRC中以绝对优势获得了冠军。
ResNet的核心贡献在于解决了深度神经网络的“退化问题”"Degradation Problem",使得训练数百层甚至上千层的神经网络成为可能。
- 想象一下我们在玩“传话游戏”。
输入输出:你看到了一张“猫”的照片,你要描述给下一个人。
深层网络:如果中间隔了100个人(100层的神经网络)。
结果:传到最后一个人时,信息可能已经严重失真了,变成了“虎”或者完全不知道是什么的东西。
这就是退化问题,层数太多,信息在传递过程中丢失了。
- ResNet的绝招:随身带个“小抄”。
ResNet的发明者想了一招:跳跃连接"Shortcut Connection"。
还是那个传话游戏,但这次规则变了:第1个人传给第2个人的时候,不仅口头描述,还塞了一张小抄给第2个人。第2个人处理完信息后,把处理结果和这张纸条加在一起,再传给第3个人,同时也把纸条复印一份传下去。
这样做的好处是:哪怕中间某个人(某一层网络),脑子短路了完全没听懂前一个人在说什么(输出为0),他手里至少还有那张“小抄”(原始信息$x$)。他可以直接把小抄递给下一个人。
那么,最差的情况下,这一层网络什么都不做,也不会把原本的信息搞丢。这就是所谓的恒等映射"Identity Mapping"。
- 什么是“残差”?
“残差”这个词听起来很高深,其实就是差值!
以前的神经网络:试图直接学会“最终答案”。这很难,就像让你直接画出一幅蒙娜丽莎。
ResNet:试图学会“还需要修改多少”。
手里已经有了上一层的答案(小抄$x$)。这一层只需要去学“当前答案和正确答案之间的差值”,即残差$F(x)$。最终输出 = 小抄 + 差值, $H(x) = x + F(x)$。
'''6_1'''
class ResidBlock(nn.Module):
"""残差块,卷积层->批量归一化->激活函数->卷积层->批量归一化->跳跃连接->激活函数。"""
def __init__(self, chann_in, chann_out, use_11_conv=False, stride=1):
super().__init__()
self.cv1 = nn.Conv2d(chann_in, chann_out, kernel_size=3, padding=1, stride=stride)
self.cv2 = nn.Conv2d(chann_out, chann_out, kernel_size=3, padding=1)
if use_11_conv:
使用1×1卷积层,调整通道数和分辨率。
self.cv3 = nn.Conv2d(chann_in, chann_out, kernel_size=1, stride=stride)
else:
self.cv3 = None
self.bn1 = nn.BatchNorm2d(chann_out)
self.bn2 = nn.BatchNorm2d(chann_out)
def forward(self, X_4D):
Y_4D = F.relu(self.bn1(self.cv1(X_4D)))
Y_4D = self.bn2(self.cv2(Y_4D))
if self.cv3:
X_4D = self.cv3(X_4D)
return F.relu(Y_4D + X_4D)上面的ResidBlock将生成2种类型的残差网络,
1️⃣use_11_conv=False如左图所示;
2️⃣use_11_conv=True如右图所示;
'''6_2'''
X_4D = torch.rand(size=(4, 3, 6, 6))
输入和输出形状一致的情况。
rsd_blk = ResidBlock(3, 3)
Y_4D = rsd_blk(X_4D)
print(Y_4D.shape)
输出形状,增加通道数,减少高和宽。
rsd_blk = ResidBlock(3, 6, use_11_conv=True, stride=2)
Y_4D = rsd_blk(X_4D)
print(Y_4D.shape)
'''6_3'''
class ResidualNet(nn.Module):
"""残差神经网络。"""
def __init__(self, ):
super().__init__()
self.stage1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.stage2 = self._make_stage(64, 64, 2, True)
self.stage3 = self._make_stage(64, 128, 2)
self.stage4 = self._make_stage(128, 256, 2)
self.stage5 = self._make_stage(256, 512, 2)
self.glolayer = nn.Sequential(nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
def _make_stage(self, chann_in, chann_out, num_residuals, first_block=False):
"""生成一个stage,包含num_residuals个ResidBlock。"""
if first_block:
# 第1个残差块,即stage2,不使用1×1卷积层。
blk_list = [ResidBlock(chann_in, chann_out)]
else:
# 后续stage3,4,5,使用1个1×1卷积层。
blk_list = [ResidBlock(chann_in, chann_out, True, 2)]
for _ in range(num_residuals-1):
blk_list.append(ResidBlock(chann_out, chann_out))
return nn.Sequential(*blk_list)
def forward(self, X_4D):
X_4D = self.stage1(X_4D)
X_4D = self.stage2(X_4D)
X_4D = self.stage3(X_4D)
X_4D = self.stage4(X_4D)
X_4D = self.stage5(X_4D)
return self.glolayer(X_4D)
'''6_4'''
def check_shape(block, X_4D):
if isinstance(block, nn.Sequential):
若是Sequential容器,则递归解包,深入内部。
for subblk in block.children():
X_4D = check_shape(subblk, X_4D)
else:
若是基本层(如Conv2d)或自定义块(如ResidBlock),直接前向传播并打印输出形状。
X_4D = block(X_4D)
print(f"{block.__class__.__name__:>20} output shape:\t{X_4D.shape}")
return X_4D
'''6_5'''
kmh_net = ResidualNet()
输入必须是4维,BCHW,BatchSize, Channel, Height, Width
X_4D = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for block in kmh_net.children():
X_4D = check_shape(block, X_4D)
'''6_6'''
Chapter01.training_classifier_1on_fashion_mnist(
kmh_net, gpu, 10, 0.05, iterate_devset, iterate_testset)
